
“A smart contract is a computer program that directly controls some kind of digital asset… The smart contract approach says instead of a legal contract, immediately transfer the digital asset into a program, the program automatically will run code, validate a condition, and determine whether the asset should go to one person or back to the other person, or whether it should be immediately refunded to the person who sent it or some combination thereof.”
Vitalik Buterin, Founder of Ethereum
Smart contracts are dynamic, complex, and incredibly powerful. This technology has the potential to change how business is done because governments and companies can decrease costs, automate contract enforcement, and provide an auditable trail of control. While their long-term potential is unimaginable, they are already disrupting industries such as crowdfunding, law, and insurance. However, smart contracts are made by humans, and therefore, they are not perfect. Over $2.4 billion USD have already been lost due to faulty smart contracts. The future success of utility tokens depends on the ability of developers to build more secure applications that users can trust.
Smart Contracts, Decentralized Applications, and Decentralized Autonomous Organizations
With the rise of cryptocurrencies and blockchains, smart contracts, Decentralized Applications (DApps), and Decentralized Autonomous Organizations (DAOs) are becoming increasingly important technologies that investors should understand. This all began when Nick Szabo coined the term “smart contract” in 1994. To define the term, a smart contract is a piece of software that represents a set of rules that are automatically executed under pre-determined circumstances. In other words, a smart contract is an “if-then” statement that is executed on a distributed peer-to-peer network.
Since each contract is stored on several computers all around the world, smart contracts do not have a single point of failure. Similar to BitTorrent, not having a single point of failure means that if one computer fails, the whole network does not fail. Nobody has the power to change the smart contract – even the person who made the smart contract. That applies to hackers and governments too!
Smart contracts have the same privileges as cryptocurrency wallets, except they are not controlled by private keys or users. Instead, a smart contract is controlled by the code contained within the smart contract. They can send and receive cryptocurrency, and they can store a balance or have a balance of zero. They can interact with other smart contracts, but users have to pay a small fee to the blockchain network to interact with the contract because every change needs to be approved and recorded by every computer that maintains the network. This is similar to mining in Bitcoin.
A DApp is a collection of many smart contracts that are working together to create a product for users. To be a DApp, four criteria must be met. First, the application must be open-source, which means that anyone can download it and look at the underlying code. Second, the application must run on a blockchain or distributed ledger technology, such as a directed acyclic graph. Third, the application must have a token associated with it. This token can be native to the application, such as Augur, or the application can use another cryptocurrency, such as Bitcoin or Ethereum. Finally, the application must use a cryptographic algorithm for confirming changes to the smart contracts that control the DApp.
A DAO is a type of DApp that allows owners to make business decisions by voting electronically and to automate management using smart contracts. DAOs use smart contracts to facilitate digital voting, and to facilitate the voting outcomes. The goal of a DAO is to reduce managerial overhead and to circumvent regulations particular to geographic regions.
Essential, a DAO is a company structure for a globally dispersed group of owners. The cryptography and blockchain enables a group of strangers to invest capital together and make financial decisions. Smart contracts enable the company to be run autonomously because they hold the rules of the company and serve as a basis for operation decisions instead of a human. For example, a smart contract could be programmed to distribute dividends to investors once a certain condition is met. If profits are above a certain threshold, the smart contract could automatically send a transaction to shareholder wallets.
Smart Contract Theory Applied In Practice
The most popular cryptocurrency that incorporates smart contracts is Ethereum. The founder of Ethereum, Vitalik Buterin, proposed Ethereum in 2013 as a blockchain specifically designed for smart contracts. Ethereum is a worldwide network of computers which enforce, execute, and validate smart contracts. As covered in the previous Crypto Research Report, validation is achieved by a decentralized network of thousands of Ethereum nodes around the world. The centralized nature of the network enables decentralized applications (DApps) to run without downtime, censorship, or third-party interference, which makes the applications immutable or tamper-proof.
In practice, Ethereum can be used to create a decentralized crowdfunding website without intermediaries, such as Kickstarter. Ethereum users can invest in a business idea by sending money to an Ethereum wallet address of a smart contract. If the entrepreneur is unable to raise a certain amount of funding within a certain timeframe, the smart contract can automatically send all of the investors their money back. Instead of paying 10 % to Kickstarter, they only have to pay a 5-cent fee to the Ethereum network to process the transaction to the smart contract. Middleman removed. If company raises $10 million with Ethereum instead of Kickstarter, they save $1 million in fees.
The decentralized nature of Ethereum also allows investors to circumvent regulations that limit how much investors can invest in crowdfunding projects. For example, in the US, non-accredited investors with an annual income or net worth less than $107,000, are limited to invest a maximum of 5 % of their assets. For those with an annual income or net worth greater than $107,000, he/she is limited to investing 10 % of the lesser of the two amounts. These rules do not apply to Ethereum and other smart contract platforms such as NEO and EOS.
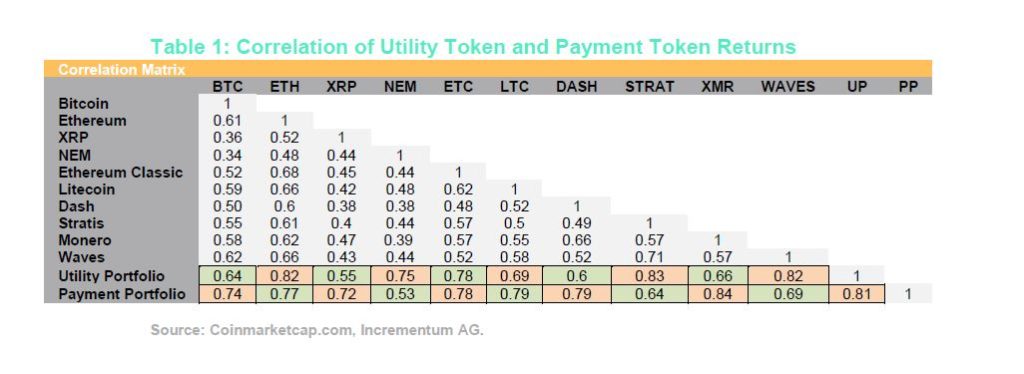
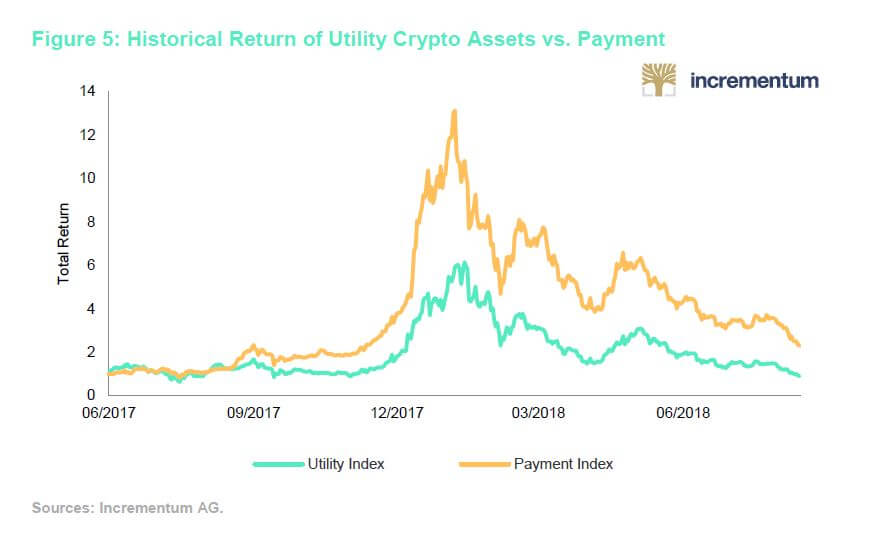
Blockchains that facilitate smart contracts are often referred to as utility blockchains, and the assets that are associated with them are referred to as utility crypto assets or utility tokens. Table 1 compares the relative return of utility crypto assets to payment crypto assets such as Bitcoin, Monero, and Litecoin. Although a portfolio comprised entirely of payment crypto assets had a higher cumulative return of 227 %, the portfolios are highly correlated with a 0.81 correlation coefficient. Cryptocurrency investors that bought the top five payment cryptocurrencies in June and sold in January realized a six-month profit of over 1,200 %.
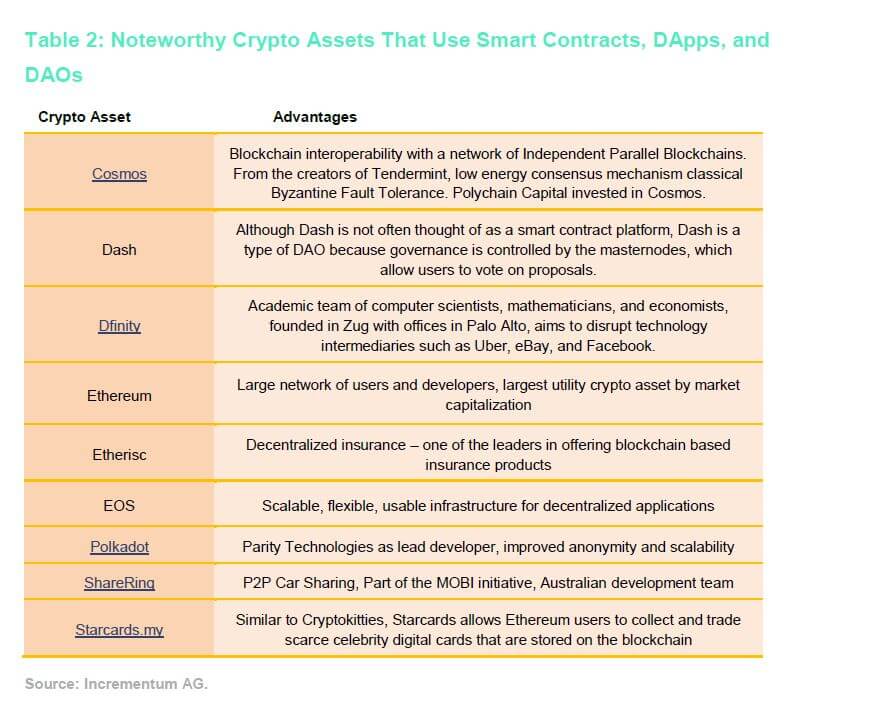
Crypto Asset Companies That Use Smart Contracts, DApps, and DAOs.
There are already many projects that seek to implement smart contracts via blockchains into the real world. Ethereum is one of the most prominent examples, but a variety of other companies are also harnessing the power of automatic digital contracts, including Cosmos, Dfinity, Etherisc, Polkadot, and ShareRing.
A controversial example is the decentralized prediction market named Augur. In late July, CNN reported on Augur users gambling on whether President Trump would be assassinated by the end of this year. Since Augur is a DApp, no one can stop users from gambling on the probability of criminal and unethical behavior. Even the creators of Augur are unable to stop Augur from existing because the project is open-source. Not only are the legality of prediction markets questionable, now lives of people will be directly attached to financial gains. If this prediction market does lead to heinous acts be committed, Augur’s price will most likely be volatile and downward.
Although Augur is enabling people to vote on the probability that Trump, John McCain, or Warren Buffett will survive past the end of this year, most of Augur’s prediction markets are based on sports. For example, during the FIFA World Cup, users could vote on the outcome of specific games and earn Ethereum if they voted correctly.
When Smart Contracts Are Dumb
Since 2011, a combined $2.4 billion has been destroyed, frozen, stolen or otherwise compromised in the crypto asset space due to attacks. The two biggest crypto assets in terms of market capitalized have seen losses of around 1.7 million BTC and 4.54 million ETH over the past seven years. The three biggest mistakes that have occurred in the Ethereum space include the DAO hack, the Parity wallet hack, and the Parity wallet suicides.
DAO Hack
The Decentralized Autonomous Organization (DAO) was one of crypto’s most highly anticipated projects of all time and a pioneer in the application of the revolutionary capabilities of smart contracts. Some of Ethereum’s developers created a spin-off company called Slock.it and created the first DAO using the Ethereum blockchain in April 2016.[1] The DAO application worked like an investment fund, although without the usual investment fund management. Investors could participate by transferring the Ethereum cryptocurrency, ether, to the fund, which entitled them to voting rights. The investment decisions were supposed to be taken through a joint effort, where every participant could vote on investment proposals. Anyone with a venture project could pitch their idea to the DAO community in hopes of potentially receiving funding from a pool of ether which was controlled by the DAO.[2] Once a project was chosen, token holders would receive rewards – much like dividends or interest payments – if the projects turned out to be profitable.
The DAO was launched as a smart contract on the Ethereum network in May 2016. At the time, it raised $162 million worth of ether, making it the biggest crowdfund ever.
Nevertheless, on June 17th, 2016, a hacker perpetrated the DAO network by exploiting a loophole in its software, allowing him to drain funds from the pool of Ethereum tokens owned by the DAO network. 3.6 million ETH tokens were stolen in the first couple of hours of the attack, amounting to an equivalent value of $70 million at the time ($1.2 billion in today’s terms). Strangely enough, the hacker stopped draining the DAO for unknown reasons, even though he could have continued to do so.
The team and community behind Ethereum were quick in noticing the breach and very soon responded to the situation by presenting multiple proposals on how to deal with the attack. Due to the architecture of the DAO, the drained funds in the form of ether were locked up in a child DAO, another smart contract, which required a 28-day holding period before the attacker could fully withdraw the funds and launder them into circulation. This gave the Ethereum team sufficient time to decide on their course of action.
Vitalik Buterin, the creator of Ethereum, realized the severity of this breach and issued a statement soon afterwards assuring all investor that their funds were safe for the moment. The Ethereum community then decided to render any transaction originating from the attackers account with code hash:
0x7278d050619a624f84f51987149ddb439cdaadfba5966f7cfaea7ad44340a4ba
as invalid, thereby preventing the attacker from withdrawing funds even after the completion of the 28-day holding period.
The hacker later published an open letter to the Ethereum community claiming rightful ownership of the acquired funds. You can see the original letter here. Refunding the investors’ ether would have not been possible under the rules of the Ethereum network at that time, posing an existential threat to the network as a whole.
The solution that the Ethereum foundation came up with was highly controversial.[3] They implemented a “hard fork” by releasing a new version of the Ethereum software client that did not include the hacked transactions. They re-winded the Ethereum blockchain in order to remove the hacker’s transactions. The release also included a fix to the bug that the hacker exploited. Not all of the members of the network agreed with the decision of hard forking the chain. Some dissidents left Ethereum entirely and others just continued to use the original Ethereum blockchain, which included the hacker’s transaction. This chain became called Ethereum Classic with ticker symbol ETC.
As with all of the mishappenings described in this article, none of them has arisen due to the fundamental design of the Ethereum network. Instead, the hacks occurred because of design problems in applications that were built on top of Ethereum. The type of attack that destroyed the DAO is known as a reentrancy attack.[4] In this attack, the attacker first donated ether to the smart contract (DAO) and then was able to “ask” for the ether back multiple times before the smart contract could update its balance. When the contract fails to update its state (a user’s balance) prior to sending funds, the attacker can continuously call the withdraw function to drain that contract’s funds.[5] The code written for the DAO had multiple flaws including the recursive call exploit as well as the fact that the smart contracts sent ETH funds before updating the internal token balance.

Parity Wallet Hack
Parity Technologies builds platforms and applications, and it powers large parts of the infrastructure of the public Ethereum network.[6] On the July 19th, 2017, an unknown hacker attacked a critical vulnerability in the Parity multisignature wallet on the Ethereum network, looting three massive wallets containing a combined $31 million worth of ETH in a matter of minutes.[7] A group of heroic white-hat hackers from the Ethereum community responded by quickly alerting Ethereum users on social media and hacking the remaining wallets before the attacker could. This form of hacking is called white-hat hacking because they hacked for the good cause. If the white hackers had not responded so quickly, the hacker could have hacked over $180,000,000 worth of Ethereum from vulnerable wallets. Of course, the funds that were stolen by the white-hats were securely redistributed to their respective account holders in the end.
The hacker found a programmer-induced bug in the code that let him re-initialize the Parity multisignature wallet, almost like restoring your iPhone to factory settings. Once having done that, he was free to set himself as the new owner and walk out with everything.
Due to the programming model of Ethereum, there is an incentive for programmers to optimize code in order to minimize transaction costs. Every time code is executed on Ethereum, a smart contract, which constitutes a transaction on the network and thus comes with a computation fee, needs to be deployed. An efficient way to reduce costs from the computation fees is to use shared libraries which have already been deployed to the network.
The default settings for the multisignature wallet in Parity had a configuration which did exactly that. It referenced a shared external library, which contained a wallet initialization logic, namely initWallet(), which if called could reinitialize the contract the wallet was built upon. It effectively made whoever exploited this flaw the new owner of the wallet. From there, the hacker could simply transfer the funds to any address of his or her choice.
However, why did they not just roll back this hack, like they did with the DAO hack? Unfortunately, that was not even an option any more. When the attacker drained the DAO into a child DAO the hacked funds were frozen for a 28-day period before they could be released to the attacker. This prevented any of the stolen funds from going into circulation, which in turn gave the Ethereum community plenty of time to consult the community about how to deal with the attack. In the Parity wallet attack, however, the attacker directly withdrew the funds and could start spending them. Once the stolen ETH was in circulation, it was almost impossible to recover them, much like with a huge sum of counterfeit bills circulating in the economy.
Parity Wallet Suicides
On November 6th, 2017, the Parity multisignature wallet fell prey to yet another attack,[8] only this time to one of a much more severe magnitude. A Github user named devops199 wrote a post titled “anyone can kill your contract”. Devops199’s post seemed to have good intentions.[9] He wanted to make the Parity team aware of a vulnerability in the smart contract that powered its multisignature wallets. The security vulnerability allowed any hacker to make him- or herself the “owner” of that contract, thus giving him or her permission to do with the wallet as he or she pleases. Up to this point in time, it still remains unclear what his original intent was, but his following actions were largely met with skepticism: He “accidentally” triggered the “kill switch” of the contract, rendering all Parity multisignature wallets impossible to access. Just minutes after the library was wiped out, devops199 raised another issue following up his “anyone can kill your contract” post on Parity’s Github titled “I accidentally killed it.”
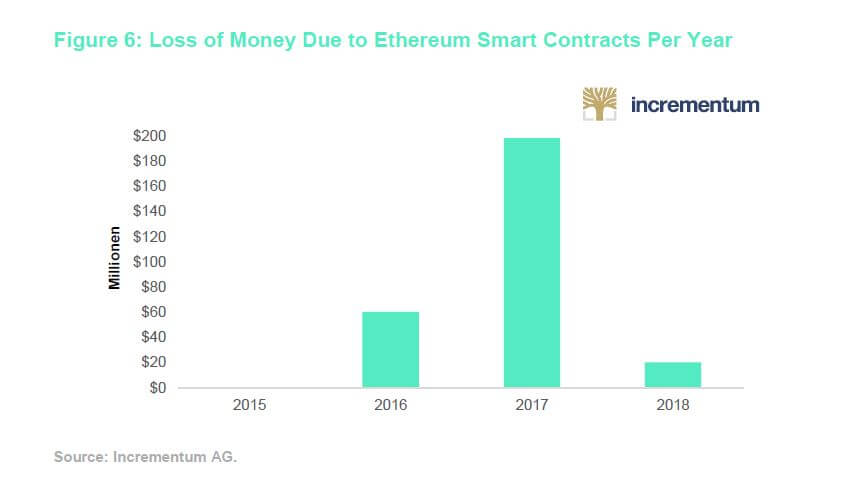
The scale of this Parity hack compromised a total of 514 k Ethereum tokens, which
at the time were valued roughly around $155 million or 1 % of Ethereum’s total
valuation. As a consequence of the hack, no funds can ever be moved out of all
Parity multisignature wallets that were deployed after July 20th, 2017 again.
A hard-fork could technically “bail-out” the multisignature wallets that are frozen
but that would compromise the foundation of Ethereum’s decentralized,
distributed, immutable, and tamper-proof ledger. Calls for a hard-fork have largely
remained ineffective.
Smart Contracts Represent a Distinctly Different Exposure for Investors Than Bitcoin
Smart contracts have the potential to disrupt industries by cutting out middlemen and bringing together the parties of the contracts directly. They can ensure trust and cut transaction costs. Despite the benefits, The Economist criticizes the concept of smart contracts by pointing out the immature state of the industry.[10] They further argue that smart contracts are not flexible enough for an economy that needs to respond to ever changing conditions.
At Incrementum, we think that smart contracts are here to stay. From a financial perspective, utility blockchains, such as Ethereum, NEO, and EOS, offer a distinctly different risk-return profile compared to payment blockchains, such as Bitcoin, Dash, and Monero. Due to the complex nature of smart contracts, utility blockchains are inherently more prone to technology risk. In contrast, since utility tokens do not threaten to disrupt the current monetary system, risk of being outlawed for competing with sovereign currencies is lower when compared to public payment blockchains. However, many regulators are saying that initial coin offerings and utility tokens are violating security law. Diversifying into both crypto asset classes is prudent for investors that are willing to make the extra effort.
[1] See “Decentralized Autonomous Organization to Automate Governance. Final Draft – Under Review” [white paper], Christoph Jentzsch, 2016.
[2] See “The Story of the DAO–Its History and Consequences,” Samuel Falkon, The Startup, December 24, 2017.
[3] See “To fork or not to fork,” Jeffrey Wilcke, Etherum Blog, July 15, 2016.
[4] See “Smart Contract Attacks [Part 1] – 3 Attacks We Should All Learn From The DAO,” Pete Humiston, Hackernoon, July 5, 2018.
[5] You can find a more technical walkthrough here.
[6] Learn more about Parity here
[7] See “A hacker stole $31M of Ether – how it happened and what it means for Ethereum,” Haseeb Qureshi, Medium, July 20, 2017.
[8] See “Security Alert,” Parity, November 8, 2017.
[9] See “Yes, this kid really just deleted $300 MILLION by messing around with Ethereum’s smart contracts,” Thijs Maas, Hackernoon, November 8, 2017.
[10] See “Not-so-clever contracts,” Schumpeter, The Economist, July 28, 2016.



{kind=link}